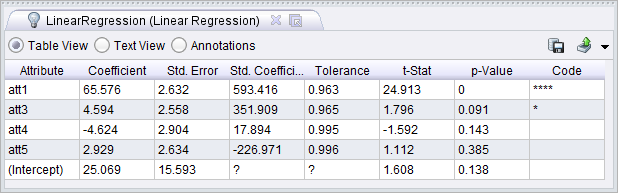
The picture below shows a process that computes multiple different aggregations of an example set.
When doing exploratory data analysis it is often useful to see what the data looks like from many different angles and part of this can involve generating new attributes based on existing attributes.
This graphic shows one of the results where two range attributes are calculated based on the difference between the minimum and maximum for the age and earnings attributes for each grouping.
With aggregation, the names of the generated attributes contain parentheses that indicate how the attribute was generated. In the example, the attribute name for the average of the ages for a particular group is "average(age)". This is fine until you want to calculate something from this attribute at which point, the parentheses make using of the "Generate Attributes" operator difficult. This is still OK because you have to rename the attribute to remove these parentheses but doing this many times on different example sets soon becomes onerous and error prone especially if you have to make changes later on.
To help with this, I created this
process. This contains three aggregations being performed for different attribute groupings. The attributes "age" and "earnings" are aggregated so that minimum and maximum values are calculated. For these aggregated values, the differences are calculated to produce ranges. In order to avoid having to cut and paste the operator chain to perform these calculations, the process allows them to be defined once so that each example set is applied to this. By doing this, the overhead of maintaining multiple copies is reduced as well as possibility of making mistakes.
This picture shows what is inside the subprocess.
This picture shows what is inside the "Loop Collection" operator
The process works as follows.
- The three aggregated example sets are connected to a subprocess
- Inside this subprocess, the "Collect" operator creates a collection from them
- The "Loop Collection" operator iterates over all the members: in this case three times
- The inner operators to the "Loop Collection" operator perform the renaming and attribute generation
- The "Multiply" operator creates three copies of the collection
- The "Select" operators choose one of the examples to pass to the output ports of the subprocess
The end result is new attributes in the example sets all generated in the same way. Changes to this calculation can be done in one place thereby making life a bit easier.