I needed to convert some numerical IP addresses to a human understandable form the other day. After writing a Groovy script to do this, I found a simpler way; use built in database functions. For example, MySQL has the function INET_NTOA() to convert IP addresses from numerical to dotted form. It is called using a select statement like this.
select INET_NTOA('123456789') as ipaddress;
This returns the value '7.91.205.21' and can be called using the "Read Database" operator.
Obviously, you would use parameters to construct the query in the general case and a loop would be needed to iterate over multiple examples. Performance might be slow for large data sets.
Sunday, 30 December 2012
Saturday, 22 December 2012
Processing value series
Value series are tricky to get working and in fact, there are some operators that I just can't make work.This is not the end of the world but to save head scratching time, here is some explanation and a process that captures the essential features of value series for reference purposes. The process finds the frequencies contained in some artificial data in two ways using value series techniques and in so doing, the results can be checked against one another to give insight into how value series work.
The first thing to say is that there are two types of value series operator. One type works on example sets, the other on example sets that have been transformed into series.
The first type is contained in the sub group "Data Transformation" and includes operators like "Differentiate" and "Integrate". These require an example set and require one attribute to be selected for processing. The operators assume the examples in the example set are an ordered time series and the attributes represent how data varies as a function of the examples.
The second type - the subject of this post - includes operators in the "Series Transformation" group. Here, the operators require a series object and these are produced using the "Process Series" operator or the "Data To Series" operator. This latter operator works in two ways; either by treating the attributes in an example as members of the series ("series_from_attributes"), or by using one particular attribute as the series variable with the ordering dictated by the example set ("series_from_examples").
One important point in the "series_from_attributes" mode is that only a single example within an example set can contribute to the series. This means that filtering of examples must happen in order to produce a series and this must happen in a loop to perform the processing on each example.
Putting all this together, the following picture shows the top level view of a process that uses both the "Process Series" and "Data To Series" operators.

The generated data is a superposition of three random sine waves with random amplitudes. The top branch shown below performs a Fourier analysis on the data and uses the "Extract Peak" operator to find the maxima of the frequency spectrum. The "Process Series" operator uses the attributes in a single example to generate the series to pass to the inner operators. In effect, this operator is iterating over all the examples in an example set.

The resulting example set looks like this

As can be seen, example 1 has a maximum at 117 and a secondary peak at 318. Example 2 has a maximum at 367 and another at 350 and so on.
The lower branch processes the data using a different series approach. The picture below shows the inner operators within the "Loop Examples" operator.

The output from one iteration of the loop is fed back to the next iteration and to make this work requires the example set to be passed straight through via the "Multiply" operator. The second output is generated by the following steps
Shown below are the graphs for the first (red) and second (blue) examples. As can be seen, the peaks match what was calculated above.

In real life, you would probably not use both approaches in the same process. The "Process Series" operator is generally easier to use since it acts as a shortcut but if your data is encoded as examples then you either have to use the "Data To Series" approach or do some windowing to convert adjacent examples into attributes.
The first thing to say is that there are two types of value series operator. One type works on example sets, the other on example sets that have been transformed into series.
The first type is contained in the sub group "Data Transformation" and includes operators like "Differentiate" and "Integrate". These require an example set and require one attribute to be selected for processing. The operators assume the examples in the example set are an ordered time series and the attributes represent how data varies as a function of the examples.
The second type - the subject of this post - includes operators in the "Series Transformation" group. Here, the operators require a series object and these are produced using the "Process Series" operator or the "Data To Series" operator. This latter operator works in two ways; either by treating the attributes in an example as members of the series ("series_from_attributes"), or by using one particular attribute as the series variable with the ordering dictated by the example set ("series_from_examples").
One important point in the "series_from_attributes" mode is that only a single example within an example set can contribute to the series. This means that filtering of examples must happen in order to produce a series and this must happen in a loop to perform the processing on each example.
Putting all this together, the following picture shows the top level view of a process that uses both the "Process Series" and "Data To Series" operators.


The resulting example set looks like this
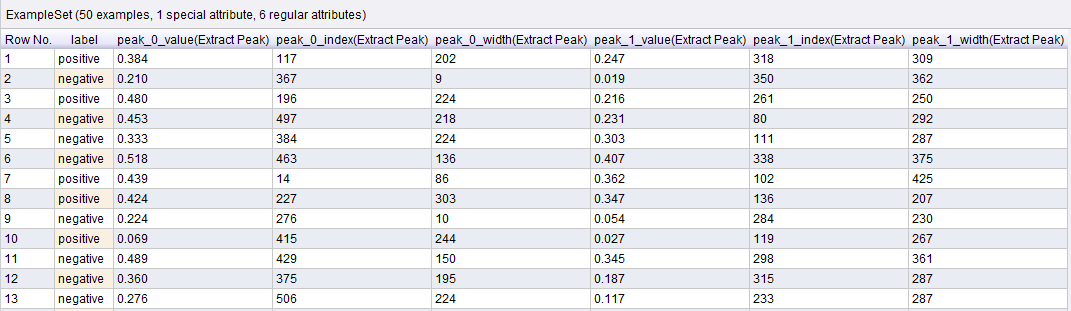
As can be seen, example 1 has a maximum at 117 and a secondary peak at 318. Example 2 has a maximum at 367 and another at 350 and so on.
The lower branch processes the data using a different series approach. The picture below shows the inner operators within the "Loop Examples" operator.

The output from one iteration of the loop is fed back to the next iteration and to make this work requires the example set to be passed straight through via the "Multiply" operator. The second output is generated by the following steps
- Filter for the single example
- Convert to series using "series_from_attributes"
- Calculate the Fourier transform
- Convert back to an example set
- Add an attribute to show the example being processed
The output is a collection which can be combined into a single example set using the "Append" operator and following a bit of light pivoting gymnastics, graphs can be drawn of the Fourier transforms for each of the examples.
Shown below are the graphs for the first (red) and second (blue) examples. As can be seen, the peaks match what was calculated above.

In real life, you would probably not use both approaches in the same process. The "Process Series" operator is generally easier to use since it acts as a shortcut but if your data is encoded as examples then you either have to use the "Data To Series" approach or do some windowing to convert adjacent examples into attributes.
Thursday, 22 November 2012
Using the Subprocess operator to stop operator execution order from changing
When editing a large process containing a lot of branches where calculations are done for use later, the operator execution order can go wrong causing the process to fail.
For example, the following shows a relatively complex process with the operator execution order overlaid.

The operators in steps 23 to 25 are calculating a macro that is used in step 13. Clearly, the order is wrong and the process is broken and this can just happen as a result of editing the process. Luckily, this is easy to fix by using the "bring operator to front" operation but I use a trick with the "Subprocess" operator.
The following shows this.

The "Subprocess" operator at what is now step 11 fixes everything. The example set output from step 10 is not required but joining it to step 11 forces it to be executed before all the other steps that might use the macros it is calculating.
Inside the "Subprocess" operator the first input is simply copied directly to the output. The second input is not connected to anything. The following shows this.

As a bonus feature, it is also possible to use this operator to untangle and "neaten up" complex workflows as shown below in a hypothetical example.

The first input is connected to the fifth output, the second to the fourth and so on. There are no restrictions on the type of data flowing through the "Subprocess" operator so this is easy to implement with any type of connection.
For example, the following shows a relatively complex process with the operator execution order overlaid.

The operators in steps 23 to 25 are calculating a macro that is used in step 13. Clearly, the order is wrong and the process is broken and this can just happen as a result of editing the process. Luckily, this is easy to fix by using the "bring operator to front" operation but I use a trick with the "Subprocess" operator.
The following shows this.

The "Subprocess" operator at what is now step 11 fixes everything. The example set output from step 10 is not required but joining it to step 11 forces it to be executed before all the other steps that might use the macros it is calculating.
Inside the "Subprocess" operator the first input is simply copied directly to the output. The second input is not connected to anything. The following shows this.


The first input is connected to the fifth output, the second to the fourth and so on. There are no restrictions on the type of data flowing through the "Subprocess" operator so this is easy to implement with any type of connection.
Thursday, 25 October 2012
Applying the same processing to multiple example sets
The picture below shows a process that computes multiple different aggregations of an example set.

When doing exploratory data analysis it is often useful to see what the data looks like from many different angles and part of this can involve generating new attributes based on existing attributes.
This graphic shows one of the results where two range attributes are calculated based on the difference between the minimum and maximum for the age and earnings attributes for each grouping.

With aggregation, the names of the generated attributes contain parentheses that indicate how the attribute was generated. In the example, the attribute name for the average of the ages for a particular group is "average(age)". This is fine until you want to calculate something from this attribute at which point, the parentheses make using of the "Generate Attributes" operator difficult. This is still OK because you have to rename the attribute to remove these parentheses but doing this many times on different example sets soon becomes onerous and error prone especially if you have to make changes later on.
To help with this, I created this process. This contains three aggregations being performed for different attribute groupings. The attributes "age" and "earnings" are aggregated so that minimum and maximum values are calculated. For these aggregated values, the differences are calculated to produce ranges. In order to avoid having to cut and paste the operator chain to perform these calculations, the process allows them to be defined once so that each example set is applied to this. By doing this, the overhead of maintaining multiple copies is reduced as well as possibility of making mistakes.
This picture shows what is inside the subprocess.

This picture shows what is inside the "Loop Collection" operator

The process works as follows.

When doing exploratory data analysis it is often useful to see what the data looks like from many different angles and part of this can involve generating new attributes based on existing attributes.
This graphic shows one of the results where two range attributes are calculated based on the difference between the minimum and maximum for the age and earnings attributes for each grouping.

With aggregation, the names of the generated attributes contain parentheses that indicate how the attribute was generated. In the example, the attribute name for the average of the ages for a particular group is "average(age)". This is fine until you want to calculate something from this attribute at which point, the parentheses make using of the "Generate Attributes" operator difficult. This is still OK because you have to rename the attribute to remove these parentheses but doing this many times on different example sets soon becomes onerous and error prone especially if you have to make changes later on.
To help with this, I created this process. This contains three aggregations being performed for different attribute groupings. The attributes "age" and "earnings" are aggregated so that minimum and maximum values are calculated. For these aggregated values, the differences are calculated to produce ranges. In order to avoid having to cut and paste the operator chain to perform these calculations, the process allows them to be defined once so that each example set is applied to this. By doing this, the overhead of maintaining multiple copies is reduced as well as possibility of making mistakes.
This picture shows what is inside the subprocess.

This picture shows what is inside the "Loop Collection" operator

The process works as follows.
- The three aggregated example sets are connected to a subprocess
- Inside this subprocess, the "Collect" operator creates a collection from them
- The "Loop Collection" operator iterates over all the members: in this case three times
- The inner operators to the "Loop Collection" operator perform the renaming and attribute generation
- The "Multiply" operator creates three copies of the collection
- The "Select" operators choose one of the examples to pass to the output ports of the subprocess
The end result is new attributes in the example sets all generated in the same way. Changes to this calculation can be done in one place thereby making life a bit easier.
Tuesday, 9 October 2012
Counting words and sentences in documents
I discovered a neat trick to allow the number of tokens within a document to be calculated and extracted in many different ways in one "Process Documents" operation.


An example process is here. This calculates details of words and sentences within a small document.
It works by applying the "Tokenize" operator to fresh copies of the document and then using the "Aggregate Token Length" operator to extract various items of meta data relating to the tokens that have been created.
The following graphic shows the detail within the "Process Documents" operator with the execution order shown.

The execution order is important. The first chain of operators labelled from 2 to 5 extracts information relating to sentences. The resulting tokens are then thrown away but the meta data is retained. The second chain from 6 to 9 extracts information relating to words. The meta data is added to the example set returned by the "Process Documents" operator but the example set will be based on the word tokenization at the end of step 9. This means that meta data relating to sentences can be included in word vectors based on words. This can be extended to tokenize in arbitrary ways.
The result for the example looks like this.

This shows there are 9 sentences each of length 137 characters in the example document. In addition there are 184 words of average length 5.527 characters.
Saturday, 15 September 2012
Selecting attribute subsets using macros: a minor foible and workaround.
It is completely possible in RapidMiner to use macros as parameters to the "Select Attributes" operator but there are a couple of things to bear in mind.
Firstly, when displaying the parameters for the operator, the macro's "%", "{" and "}" are suppressed from the display as shown below.

Checking the XML reveals that all is well.

Secondly, there is another more subtle point. If the macro has been defined in the process context, its value is substituted into the parameter list. So in the example above, if the macro "id_attribute" had the value "fred" in the process context, this value is explicitly placed in the operator's parameters. That's fine for a local process but it makes it impossible to execute a process containing a macro used in this way if you want to pass a different value to the macro. Fortunately, it's easy to work around. Just ensure that any macros referenced in attribute selection do not exist in the process context by creating them using the "Set Macros" operator and setting their values to those already in the context.
Firstly, when displaying the parameters for the operator, the macro's "%", "{" and "}" are suppressed from the display as shown below.

Checking the XML reveals that all is well.

Secondly, there is another more subtle point. If the macro has been defined in the process context, its value is substituted into the parameter list. So in the example above, if the macro "id_attribute" had the value "fred" in the process context, this value is explicitly placed in the operator's parameters. That's fine for a local process but it makes it impossible to execute a process containing a macro used in this way if you want to pass a different value to the macro. Fortunately, it's easy to work around. Just ensure that any macros referenced in attribute selection do not exist in the process context by creating them using the "Set Macros" operator and setting their values to those already in the context.
Wednesday, 1 August 2012
Deleting attributes with 2 valid values and the rest missing
For some reason the other day, I can't remember why, I had to delete attributes with two valid values and all the rest missing. It followed on from this process.
So I made this process that finds all attributes with a specific number of valid values and removes them (the attributes).
This example uses sample data so deletes attributes with 7 valid values but I'm sure you'll get the idea.
So I made this process that finds all attributes with a specific number of valid values and removes them (the attributes).
This example uses sample data so deletes attributes with 7 valid values but I'm sure you'll get the idea.
Wednesday, 25 July 2012
Converting pdf to text
Sometimes, the "process documents from files" operator can fail when it encounters a "dodgy" pdf and it is not possible to ignore this error using the "handle exception" operator (or at least I couldn't find a way).
Up to now, I wasn't too bothered by this, but a recent thread on reddit, motivated me to try and work round the problem.
I came up with a Groovy script that uses the third party tool "pdfbox" to convert pdf to text. This is done using a combination of Groovy script and command line execution.
To recreate this, follow these steps.
Step 1 - download pdfbox from here.
Install it and remember its location, this will get used later.
Step 2 - In the RapidMiner process where you want to access the pdfs, ensure the following macros are defined.
The command line runs the pdfbox tool, converts the pdf to text and creates a text file with the same name as the pdf but with .txt appended. The crucial thing is that it is now possible to use the "Handle Exception" operator to ignore failures of the pdfbox operation. I found that pdfs that had been created with the option to disallow copying would cause errors.
Up to now, I wasn't too bothered by this, but a recent thread on reddit, motivated me to try and work round the problem.
I came up with a Groovy script that uses the third party tool "pdfbox" to convert pdf to text. This is done using a combination of Groovy script and command line execution.
To recreate this, follow these steps.
Step 1 - download pdfbox from here.
Install it and remember its location, this will get used later.
Step 2 - In the RapidMiner process where you want to access the pdfs, ensure the following macros are defined.
- file_path - the full path to the pdf file
- file_name - the file name of the pdf file without any folder information
- outputFileLocation - the name of the folder where you want the converted pdf to be placed
- pdfboxLocation - the full name of the folder containing the pdfbox software
String file_name = operator.getProcess().macroHandler.getMacro("file_name");
String outputFileLocation =
operator.getProcess().macroHandler.getMacro("outputFileLocation");
String file_path = operator.getProcess().macroHandler.getMacro("file_path");
String pdfboxLocation = operator.getProcess().macroHandler.getMacro("pdfboxLocation");
String cmdLine = "java -jar " +
"\"" + pdfboxLocation + "\"" +
" ExtractText -force " +
"\"" + file_path + "\" " +
"\"" + outputFileLocation + file_name + ".txt" + "\"";
operator.getProcess().macroHandler.addMacro("cmdLine", cmdLine);
The command line runs the pdfbox tool, converts the pdf to text and creates a text file with the same name as the pdf but with .txt appended. The crucial thing is that it is now possible to use the "Handle Exception" operator to ignore failures of the pdfbox operation. I found that pdfs that had been created with the option to disallow copying would cause errors.
Monday, 16 July 2012
Chopping files into smaller bits
I had trouble processing a large csv file recently because it was nearly 100Mb in size and it was not possible given the resources available in my laptop to process it and subsequently insert the whole lot into a database.
So I created a process to take the file and chop it up into smaller bits so I could process these and insert into the database. This took time but at least it finished.
Here is an example process to chop csv files. This creates a large csv file by way of illustration and then proceeds to split it using the "loop batches" operator.
Remove the "generate dummy data" and "write dummy data" operators and change the macro "fileToRead" in the context to point to the location of the file you want to read.
So I created a process to take the file and chop it up into smaller bits so I could process these and insert into the database. This took time but at least it finished.
Here is an example process to chop csv files. This creates a large csv file by way of illustration and then proceeds to split it using the "loop batches" operator.
Remove the "generate dummy data" and "write dummy data" operators and change the macro "fileToRead" in the context to point to the location of the file you want to read.
Sunday, 1 July 2012
Operators that deserve to be better known: part V
The "loop batches" operator splits an example set into batches for the inner operators to work on. The output is simply a copy of the full input example set. The results of the inner operators are not passed to the output because the idea is for these to process the batches perhaps by writing to a file or to a database.
When writing a large example set to a database, machine resource limits can prevent this from working so batching is a good way to proceed.
An example is provided. This takes an example set with 100 examples and uses the "loop batches" operator to write each batch to a file. A macro is used to make the file names unique.
When writing a large example set to a database, machine resource limits can prevent this from working so batching is a good way to proceed.
An example is provided. This takes an example set with 100 examples and uses the "loop batches" operator to write each batch to a file. A macro is used to make the file names unique.
Saturday, 16 June 2012
Operators that deserve to be better known: part IV
The "Materialize Data" operator can be very useful. It has the effect of making a fresh copy of the data which I take to mean the example set or sets. Using this operator can often cure some tricky problems.
As an example, here is a process that does a simple cross validation on the sample sonar data set (you may have to change the location for your setup). Inside the cross validation the intermediate training and test data sets are remembered. In a later loop, these saved example sets are recalled. This shows details of how cross validation works.
The "Remember" operator fails to save the correct example if the preceding "Materialize Data" is disabled. In addition, the collection that is recalled later does not display correctly (on my 64 bit Windows machine). Enabling the "Materialize Data" operator restores correct operation.
As an example, here is a process that does a simple cross validation on the sample sonar data set (you may have to change the location for your setup). Inside the cross validation the intermediate training and test data sets are remembered. In a later loop, these saved example sets are recalled. This shows details of how cross validation works.
The "Remember" operator fails to save the correct example if the preceding "Materialize Data" is disabled. In addition, the collection that is recalled later does not display correctly (on my 64 bit Windows machine). Enabling the "Materialize Data" operator restores correct operation.
Wednesday, 9 May 2012
Reading and writing xlsx files in RapidMiner
The other day, I stumbled on a nifty way to import and export xlsx files into and out of RapidMiner.
There's an R package called "xlsx" that is able to read and write Excel files including Excel 2007 xlsx format.
Here's a process that loads the iris data, writes this to an xlsx file at c:\temp\iris.xlsx and then reads it back again.
(Note: after the first run, comment out the line in the R script that installs the xlsx package to avoid downloading the R package again)
Edit: 12/7/12: The new version of RapidMiner supports this - hurrah!
There's an R package called "xlsx" that is able to read and write Excel files including Excel 2007 xlsx format.
Here's a process that loads the iris data, writes this to an xlsx file at c:\temp\iris.xlsx and then reads it back again.
(Note: after the first run, comment out the line in the R script that installs the xlsx package to avoid downloading the R package again)
Edit: 12/7/12: The new version of RapidMiner supports this - hurrah!
Saturday, 14 April 2012
Deleting attributes with a single valid value
Removing attributes where one or more of the examples are missing is easy using the "Select Attributes" operator with the option "no missing values".
If however, you want to additionally remove attributes where only a single example is valid and all the rest are missing, a neat way to do this is to use the "Remove Useless Attributes" operator. One of the parameters to this is "numerical min deviation" and this will remove any attribute with a deviation less than or equal to the value supplied which defaults to 0. Attributes with only a single valid value will have a deviation of 0 and will therefore be removed by this operator.
If however, you want to additionally remove attributes where only a single example is valid and all the rest are missing, a neat way to do this is to use the "Remove Useless Attributes" operator. One of the parameters to this is "numerical min deviation" and this will remove any attribute with a deviation less than or equal to the value supplied which defaults to 0. Attributes with only a single valid value will have a deviation of 0 and will therefore be removed by this operator.
Thursday, 22 March 2012
Operators that deserve to be better known: part III
Normalize
Of course this is already a well known operator but it has a useful option I discovered the other day. If you set the method to "proportion transformation", the normalization divides each numerical attribute with the sum of all the values for that attribute. This has the effect that the sum of each normalized attribute becomes 1.
This is much easier than using loop operators which would involve having a "loop examples" operator inside "loop attributes" with filtering, calculating sums, generating attributes and perhaps some attribute selection.
Of course this is already a well known operator but it has a useful option I discovered the other day. If you set the method to "proportion transformation", the normalization divides each numerical attribute with the sum of all the values for that attribute. This has the effect that the sum of each normalized attribute becomes 1.
This is much easier than using loop operators which would involve having a "loop examples" operator inside "loop attributes" with filtering, calculating sums, generating attributes and perhaps some attribute selection.
Friday, 2 March 2012
Operators that deserve to be better known: part II
Execute Process
This operator allows an entire process to be run from within another. This is good if you want to break a large process into smaller and more understandable chunks. It also encourages re-use of previously created processes especially if macros are used as parameters to control the behaviour of the called process.
The process to be run can be stored in a repository located on a different computer although the process runs on the local computer.
This operator allows an entire process to be run from within another. This is good if you want to break a large process into smaller and more understandable chunks. It also encourages re-use of previously created processes especially if macros are used as parameters to control the behaviour of the called process.
The process to be run can be stored in a repository located on a different computer although the process runs on the local computer.
Monday, 13 February 2012
Outputting the names and values of macros
Sometimes you need to know the name and value of a macro that has been defined somewhere else. To help myself, I created a Groovy script that reads all the defined macros and their value and prints them to the log. Add this small Groovy script at strategic places in your process to get visibility of what is happening.
for (String macroName : operator.getProcess().macroHandler.getDefinedMacroNames()) {
String macroValue = operator.getProcess().macroHandler.getMacro(macroName);
operator.logNote ("Macro name: value: " + macroName + " : " + macroValue);
}
return input;
Edit: Version 5.3 has a new macro view that does this :)
Thursday, 19 January 2012
Reading wav files into RapidMiner using R
I prefer using RapidMiner to create complex processes. It's easier to get the big picture perspective of a process using the connected operator view. This means I tend to try and bring things into RapidMiner from elsewhere where possible.
An example of this is reading wav files; very easy in R. Here's an example process that uses R to do this and imports the results into RapidMiner.
You will need to uncomment the line in the R script to fetch the tuneR library.
You will also have to provide the path to the wav file you want to import.
There may be wav files it cannot read but this is an exercise for the reader.
An example of this is reading wav files; very easy in R. Here's an example process that uses R to do this and imports the results into RapidMiner.
You will need to uncomment the line in the R script to fetch the tuneR library.
You will also have to provide the path to the wav file you want to import.
There may be wav files it cannot read but this is an exercise for the reader.
Wednesday, 11 January 2012
Convert date to unix timestamp
Use the "Generate Attributes" operator and create an attribute with the following expression.
round (date_diff (date_parse (0), dateToConvert,"en","GMT")/1000)
round (date_diff (date_parse (0), dateToConvert,"en","GMT")/1000)
Monday, 9 January 2012
Recurrence plots
Recurrence plots are interesting - see this link for a very good Web site that explains them and what they can be used for. In particular, see this link for an animation that explains how they are made.
Inspired by this I made an example using RapidMiner. It works as follows
 For fun, I downloaded the Google share price and I made this even nicer looking picture (this shows distances less than 0.1)
For fun, I downloaded the Google share price and I made this even nicer looking picture (this shows distances less than 0.1)
 I suspect that when it comes to the application of recurrence plots to share prices there is more money in the art of looking rather than the science of predicting.
I suspect that when it comes to the application of recurrence plots to share prices there is more money in the art of looking rather than the science of predicting.
Inspired by this I made an example using RapidMiner. It works as follows
- A simple sine series is made.
- The "Windowing" operator converts the series into a set of triplets
- The "Multiply" operator makes a copy of the example set
- The "Cross Distances" operator calculates the distances between all the points in the two copies
- The "Filter Examples" operator allows filtering to be done. The smaller the distance the closer the points.


Subscribe to:
Posts (Atom)