The "Cross Distances" operator is used to determine which examples in one set are closest to those in another.
Here's an example correctly showing the first example from the first set at zero distance from the first example in the second set. In other words, these two examples match.
Here's another example that behaves unexpectedly. In this case, the first example in the first set is shown at zero distance from the first example of the second set even though the attribute names and values do not match.
The reason for this is the order of the attributes in the example sets. The attributes are created in different orders and it is this that determines which attribute pairs are compared when calculating distances. You can see this ordering if you go to the meta data view and show the 'Table Index' column. The special attributes are also important.
Normally, most will find that this is not a problem. However, if you import data from two different sources that are supposed to represent the same data but which have columns in different orders, you will find that the "Cross Distances" operator will not behave as expected.
It is possible to work round this by using the "Generate Attributes" operator to recreate attributes in both example sets in the same order.
Tuesday, 31 May 2011
Saturday, 21 May 2011
Worked example using the "Pivot" operator
Here is an example process using the "Pivot" operator that converts this input data
 into this output data.
into this output data.
 In the input data, each row corresponds to a transaction and sub transaction with an attribute value.
In the input data, each row corresponds to a transaction and sub transaction with an attribute value.
In the output data, the number of rows corresponds to the number of unique transactions. All the sub transactions for a transaction are combined. New attributes are created so that the attribute for a given sub transaction can be found by looking at the name. For example, "attribute_subTransaction2" is the attribute in the input data which comes from the "subTransaction2" rows.
This is done by setting the "group attribute" parameter of the "Pivot" operator to "transactionId" and the "index attribute" parameter to "subTransactionId". This causes grouping by "transactionId" and the values of the subTransactionId are used to create the names of the new attributes in the output data.
The "consider weights" check box allows weights to be handled although it's not clear how these would get fed into the operator; a problem for another day.
Edit: If there is a numeric attribute whose role is "weight", setting the check box above allows this to be aggregated within the group. Refer to myexperiment.org for an example.
The "skip constant attributes" check box should be left unchecked. If checked, an attribute that does not vary within the group, is ignored and will not appear in the output data. The observed behaviour seems to be a little different but that's also for another day.
The process also uses the "Generate Data by User Specification" and "Append" operators to make the fake data.
In the output data, the number of rows corresponds to the number of unique transactions. All the sub transactions for a transaction are combined. New attributes are created so that the attribute for a given sub transaction can be found by looking at the name. For example, "attribute_subTransaction2" is the attribute in the input data which comes from the "subTransaction2" rows.
This is done by setting the "group attribute" parameter of the "Pivot" operator to "transactionId" and the "index attribute" parameter to "subTransactionId". This causes grouping by "transactionId" and the values of the subTransactionId are used to create the names of the new attributes in the output data.
The "consider weights" check box allows weights to be handled although it's not clear how these would get fed into the operator; a problem for another day.
Edit: If there is a numeric attribute whose role is "weight", setting the check box above allows this to be aggregated within the group. Refer to myexperiment.org for an example.
The "skip constant attributes" check box should be left unchecked. If checked, an attribute that does not vary within the group, is ignored and will not appear in the output data. The observed behaviour seems to be a little different but that's also for another day.
The process also uses the "Generate Data by User Specification" and "Append" operators to make the fake data.
Sunday, 8 May 2011
Measuring operator performance for different sizes of data
This process measures the performance of a modelling operator as more and more examples are added. The resultant example set of performance values could be used with a regression model to allow predictions to be made about how a given model will perform with a large data set.
The following values are available for logging with the "Log" operator.
Investigations show that cpu-execution-time and cpu-time are identical and these look like they are measured in microseconds.
Execution-time, looptime and time are also identical to one another and these look like they are measured in milliseconds.
Furthermore, the microsecond values are almost always 1,000 times the millisecond values and therefore, only one of these values is required to allow the measurement to be taken.
The process uses the "Select Subprocess" operator to make it easier to change the model algorithm so avoiding having to edit the "Log" operator. Experiments showed that the timings from the select operator were, to all intents and purposes, identical to those from the enclosed operator.
Performance is not determined solely by the process, there are inevitably external factors that will impact it as other things happen on the computer. The process therefore runs each iteration for a given sample size multiple times to obtain a more statistically meaningful result.
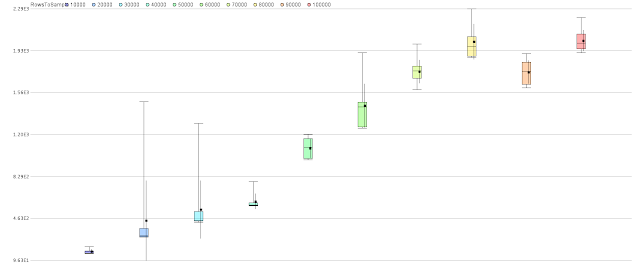
Here is an example quartile colour plot showing performance of a neural network as the number of rows is increased from 10,000 to 100,000 in increments of 10,000.

Here is an example using decision trees.
The following values are available for logging with the "Log" operator.
- cpu-execution-time
- cpu-time
- execution-time
- looptime
- time
Investigations show that cpu-execution-time and cpu-time are identical and these look like they are measured in microseconds.
Execution-time, looptime and time are also identical to one another and these look like they are measured in milliseconds.
Furthermore, the microsecond values are almost always 1,000 times the millisecond values and therefore, only one of these values is required to allow the measurement to be taken.
The process uses the "Select Subprocess" operator to make it easier to change the model algorithm so avoiding having to edit the "Log" operator. Experiments showed that the timings from the select operator were, to all intents and purposes, identical to those from the enclosed operator.
Performance is not determined solely by the process, there are inevitably external factors that will impact it as other things happen on the computer. The process therefore runs each iteration for a given sample size multiple times to obtain a more statistically meaningful result.
Here is an example quartile colour plot showing performance of a neural network as the number of rows is increased from 10,000 to 100,000 in increments of 10,000.

Here is an example using decision trees.

Sunday, 1 May 2011
How to read a PMML file to determine the attributes shown on a decision tree
Here is a process to read a PMML file created by RapidMiner.
The PMML file in this case is a model created by running a decision tree algorithm on the iris data set. Here's a snapshot - the highlighted parts are to help explain later.

The result of this XPath is to create multiple documents each containing a small section of the original document. Each section corresponds to the XML for a specific SimplePredicate entry.
Next the process turns the documents into an example set and the number of rows in this corresponds to the number of times the SimplePredicate XPath query cut the file into smaller documents. The example set is returned and after some processing the final output is a list of the attributes used in the decision tree.
In the example, attributes a3 and a4 can be seen on the decision tree and these are also output as an example set.
The PMML file in this case is a model created by running a decision tree algorithm on the iris data set. Here's a snapshot - the highlighted parts are to help explain later.

The process writes this to c:\temp\Iris.xml.pmml and then reads it back in (the subprocess operator allows this to be synchronised). The file is handled as a document by RapidMiner.
Next, the process uses the following XPath to split the document into chunks (the PMML is probably not required).
/xmlns:PMML//xmlns:SimplePredicate
The xmlns is a namespace and this is provided by the following name value pair in the "cut document" operator.
This value is provided in the raw XML and it is important to get this correct. The "assume html" checkbox is unchecked.
The XPath itself simply finds all XML nodes somewhere beneath the PMML node that correspond to "SimplePredicate". By inspection of the PMML, this looked to be the correct way of determining the fields used on the decision tree.
Within the "cut document" operator, the inner operator extracts information using more XPath. This time, the XPath is looking for an attribute named "field" and the XPath to do this is as follows.
A namespace is not required here because it looks like the document fragments don't refer to one.
In the example, attributes a3 and a4 can be seen on the decision tree and these are also output as an example set.
Subscribe to:
Posts (Atom)